In the real world, when you hear two sounds at once, what you’re hearing is the combination (in the “+” sense) of the two noises. If you put five hundred drummers in the same room and, avoiding the obvious drummer jokes for now, told them all to play, you’d get drummer 1 + drummer 2 + … + drummer 500 (also bleeding ears).
With digital audio though, the volume doesn’t go up to oh-god-please-make-them-stop – it’s limited to a small dynamic range.
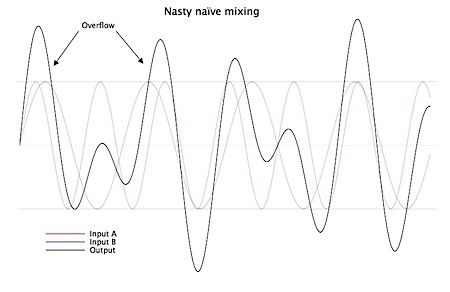
So, digital mixing actually requires a little thought in order to avoid overflowing these bounds and clipping. I recently came across this when writing some mixing routines for my upcoming app Loopy 2, and found a very useful [discussion on mixing digital audio](http://www.vttoth.com/digimix.htm) by software developer and author Viktor Toth.
The basic concept is to mix in such a way that we stay within the dynamic range of the target audio format, while representing the dynamics of the mixed signals as faithfully as possible.Note that a simple average of the samples (as in, (sample 1 + sample 2) / 2) won’t accomplish this – for example, if sample 1 is silent, while sample 2 is happily jamming away, sample 2 will be halved in volume.
Instead, we want to meet three goals – assuming signed audio samples, the standard format for Remote IO/audio units on the iPhone/iPad, which can range from negative, through to zero (silence), up to positive values.
- If both samples are positive, we mix them so that the output value is somewhere between the maximum value of the two samples, and the maximum possible value
- If both samples are negative, we mix them so that the output value is somewhere between the minimum value of the two samples, and the minimum possible value
- If one sample is positive, and one is negative, we want them to cancel out somewhat
If we’re talking about signed samples, MIN…0…MAX, this does the trick:
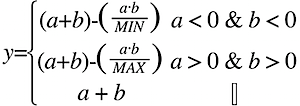
This lets the volume level for both samples remain the same, while fitting within the available range.
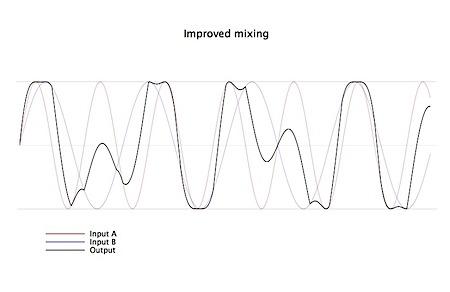
Here’s how it’s done on iOS:
SInt16 *bufferA, SInt16 *bufferB; NSInteger bufferLength; SInt16 *outputBuffer; for ( NSInteger i=0; i<bufferLength; i++ ) { if ( bufferA[i] < 0 && bufferB[i] < 0 ) { // If both samples are negative, mixed signal must have an amplitude between // the lesser of A and B, and the minimum permissible negative amplitude outputBuffer[i] = (bufferA[i] + bufferB[i]) - ((bufferA[i] * bufferB[i])/INT16_MIN); } else if ( bufferA[i] > 0 && bufferB[i] > 0 ) { // If both samples are positive, mixed signal must have an amplitude between the greater of // A and B, and the maximum permissible positive amplitude outputBuffer[i] = (bufferA[i] + bufferB[i]) - ((bufferA[i] * bufferB[i])/INT16_MAX); } else { // If samples are on opposite sides of the 0-crossing, mixed signal should reflect // that samples cancel each other out somewhat outputBuffer[i] = bufferA[i] + bufferB[i]; } } |
Update: A reader recently demonstrated that this technique can introduce some unpleasant distortion with certain kinds of input — as the algorithm is nonlinear, some distortion is inevitable (see the sharp points on the waveform where the condition switches over). For the kind of audio I’m mixing, the results seem to be perfectly adequate, but this may not be generally true.
Update 2: Here’s an inline function I put together for neatness:
inline SInt16 TPMixSamples(SInt16 a, SInt16 b) { return // If both samples are negative, mixed signal must have an amplitude between the lesser of A and B, and the minimum permissible negative amplitude a < 0 && b < 0 ? ((int)a + (int)b) - (((int)a * (int)b)/INT16_MIN) : // If both samples are positive, mixed signal must have an amplitude between the greater of A and B, and the maximum permissible positive amplitude ( a > 0 && b > 0 ? ((int)a + (int)b) - (((int)a * (int)b)/INT16_MAX) // If samples are on opposite sides of the 0-crossing, mixed signal should reflect that samples cancel each other out somewhat : a + b); } |
Wow, I have been looking for a better way to do this forever and have not found a good resource for it. This could have saved me weeks of work had I known many months ago. Keep up with the awesome audio work.
I implemented the method you described and I am finding that the estimation of the audio wave appears to be degrading the audio to a noticeable point. Did you find this as well or is it something to do with my implementation?
Hey Brett =)
I’m not noticing any problems myself, but I could be looking for the wrong thing. What’s it sound like?
If one were to mix more than 2 buffers (4 or 5, let’s say), is there a more efficient way to do it than mixing buffers 1 + 2, then mixing the result with buffer 3, etc?
Do you know you have a performance problem doing it incrementally? Unless you do, that sounds like premature optimization to me, which’ll only give you pain.
I doubt you’d see any significant performance improvements by working more terms in. Theoretically, you could work the formula through to include more terms, substitute the (a+b) – ((a•b/MIN)) terms into the same formulas replacing a, and replace b in the new formula with c, then work it through – but that’d quickly get tedious, and I’d be surprised if you actually ended up with less operations in the end, although I haven’t done a detailed analysis on it.
Your probably right — mixing the samples is still on the to-do list and I have a hard time getting out of the Ruby mentality of writing as little code as possible — but, more than a few times with RemoteIO performance-heavy stuff, writing more verbose code has turned out to let me be more efficient in some ways.
I’ll try the incremental one and see how it pans out. Thanks so much for all your articles here!
No problem!
Another thing to consider is offline processing, where appropriate – we’re meant to be as speedy as possible in the render thread, so if you can produce the audio elsewhere, and just pull it out of a buffer for the render, it may make things better.
Whoops — *You’re
This is going to kill any sort of complex audio signal, as the number of crossovers will be so many. Have you tried comparing the results of doing this along with simple mixing ([a + b]/2)? I’d suggest doing it with drum set and string quartet samples to really be able to hear it.
Why not use soft saturation, or incremental limiting?
Hey Rich,
Yeah, this scheme aint perfect – it’s fine for some kinds of audio, but definitely distorts with others (although not particularly badly – I can’t hear it, personally). (a+b)/2 has the problem that it artificially decreases the overall level, particularly if one of the signals is low or silent, which I wasn’t too keen on. I needed something that kept the level the same (but without clipping).
When I find a moment, I want to implement an a+b => limiter system, to provide the same output levels as this technique does, but sans the artefacts. Basically perform the addition in double the bit width, then smoothly adjust the amplitude envelope to pull back the hot spots.
yea limiting is the way to go, there are a few implementations of it on musicdsp.org. About (a + b)/2, I only meant to use it for comparison purposes (you’d have to boost it back up to the same maximum amplitude with a sound editor first).
Change to (A+B)+(AB/max) in the A<0, B<0 case gives a continous function. Nevertheless, this scheme will cause saturtion if a large swing signal (close to max or min) is mixed with a small singnal. The small signal will be clipped.
Hi Michael, I have been successfully using this mixing technique in an App I am developing for some months. To implement it I had to do away with the apple multichannel mixer audio unit and just do all the mixing in a single remoteio output unit (in order to get single frame mixing). However I was reading your blog and noticed you are building ‘The Amazing Audio Engine’ which one of the features if – Efficient mixing of input signals, using Apple’s MultiChannelMixer. Does this mean there is a way to implement this algorithm whilst still using a multichannel mixer? (Apples new ios5 audio units look attractive but not sure how im going to utilise them yet if im just using a single remoteio output AU…. ) Thanks!
I just did some frequency spectrum plots for this method as well as for clipping and limiting. It’s interesting to see the harmonic distortion each introduces and how it compares. Have a look…
Mixing Audio without Clipping in iOS: Limiters and Other Techniques
Nice work, Hari, a good summary.
I’m commenting here because you have comments turned off on your blog – you should probably leave them on!
Funny you should mention it, the next version of Loopy (which I’m about to submit to app review) now has a lookahead limiter instead of the piecewise mixing. The prior system was acceptably good, as you say, but I feel more comfortable with a proper professional mechanism instead.
My limiter works by keeping and updating a state variable, then applying that state to the buffer values. While it’s idle, it’s seeking ahead for values greater than the limiter’s trigger value (using vDSP_maxmgvi), and then switching to attack state if it finds one. Then it smoothly ramps (using vDSP_vrampmul) up to an active state, where the gain is applied to all values (using vDSP_vsmul), during which it continues to look ahead to see if it finds a higher trigger, in which case it increases its target gain. Then after the hold duration, it goes into decay state and smoothly restores gain to 1.0 (while continuing to seek ahead for trigger values). It can be implemented entirely in vector operations, so it’s pretty fast, and all transitions are smoothly ramped, including across buffer boundaries.
Be wary of transitions that cross buffer boundaries – your proposed algorithm runs the risk of ‘forgetting’ about ramp values across separate buffers, which will result in discontinuities.
I’ve just enabled them (been procrastinating on their finishing their CSS :p). I’ve taken the liberty of adding your comment and replying as to not hi-jack this post. Hope you don’t mind. Let me know otherwise…
Hi Michael,
I am new to audio mixing. Can you please post a complete objective c code example to mix two audio files. I am facing a crash problem while using your above code snippet.
Thanks in advance.
dirty mix of two samples
mix = (a + b) - a * b * sign(a + b)This is so terribly wrong. Please don’t mislead newbies into thinking that this is the correct way to mix two channels. The correct way is to simply sum/average them together, as you dismissed early in the article.
Summing/averaging is exactly what every professional analog or digital mixing console does, because it’s exactly what happens in the air and in our ears and in our brains. Yes, it can change the crest factor of the signal, but that’s ok because digital audio is designed to have lots of headroom for the peaks above the normal signal level that you listen at. You’re not generating audio at 0 dBFS are you? Surely you know better than that. :D
If you want to participate in the Loudness War and harshly reduce the dynamic range of your mix til everything is at 11 all the time, use a locally-linear limiter, not this nonlinear distortion stuff.