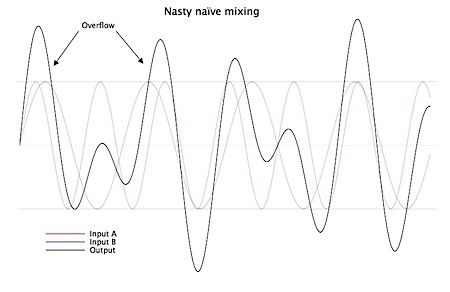
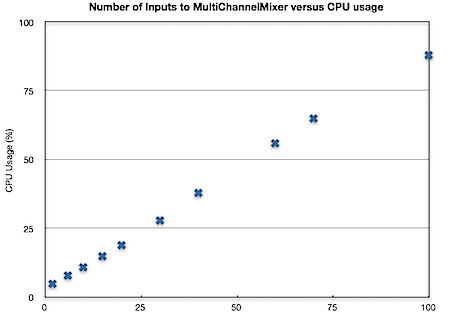
Some updates to TPCircularBuffer
I’ve recently made some updates to TPCircularBuffer (on GitHub), my C circular/ring buffer implementation, which add a memory barrier on read and write, inline the main functions for a potential performance boost, and add support for use within C++ projects.
If you’re using TPCircularBuffer at all, I recommend updating!
Read More